类别:python / 日期:2018-10-08 / 浏览:11199 / 评论:0
本文主要记录了在Windows10下通过Pycharm编写程序并在本地调用Spark运行,综合一些文章的内容,并且修改一些文章的问题。
安装环境:Win10
安装软件:hadoop2.8.5,spark2.3.2,scala2.12.7,anaconda5.2.0
0、前言
首先安装scala,到 https://www.scala-lang.org/download 下载Windows版进行安装。
然后到 https://www.anaconda.com/download/ 下载python3版本的anaconda并进行安装,安装过程中记得勾选Add PATH的选项。
接着下载Hadoop https://hadoop.apache.org/releases.html (binary包)解压缩,解压缩目录中不要有中文。
最后下载Spark http://spark.apache.org/downloads.html ,这里选择包含hadoop2.7的预编译版本下载,注意解压缩的时候要用管理员权限进行,解压缩目录中不要有中文。
然后在系统环境变量里配置好HADOOP_HOME,SPARK_HOME等环境变量。
1、使用Spark
安装成功后我们先进行测试,运行spark-shell,此时可能会出现winutils.exe文件找不到的错误。
此时到 https://github.com/steveloughran/winutils 中下载对应hadoop的winutils.exe文件。
改权限 winutils.exe chmod 777 D:\tmp\Hive,在运行命令前先创建目录 D:\tmp\Hive 。
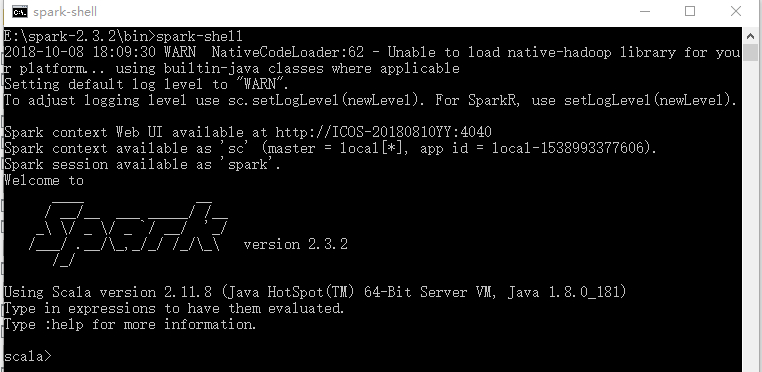
这时表示运行成功,然后运行pyspark进行测试。
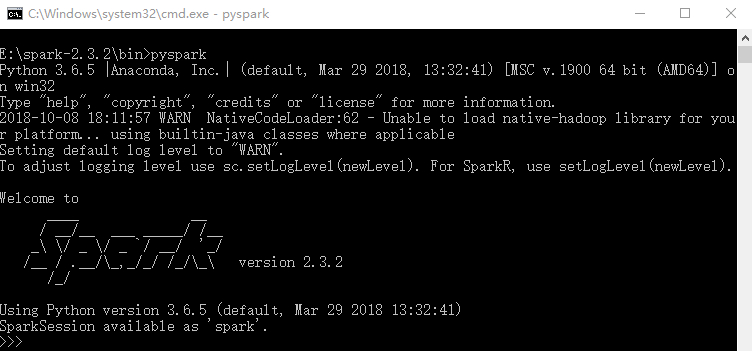
2、对PyCharm进行配置
保证anaconda已经安装完成,此时PyCharm中就可以创建conda的虚拟环境了。
创建新项目,选Pure Python,然后选择Conda虚拟环境,python版本为3.6,设置名称后点击create。
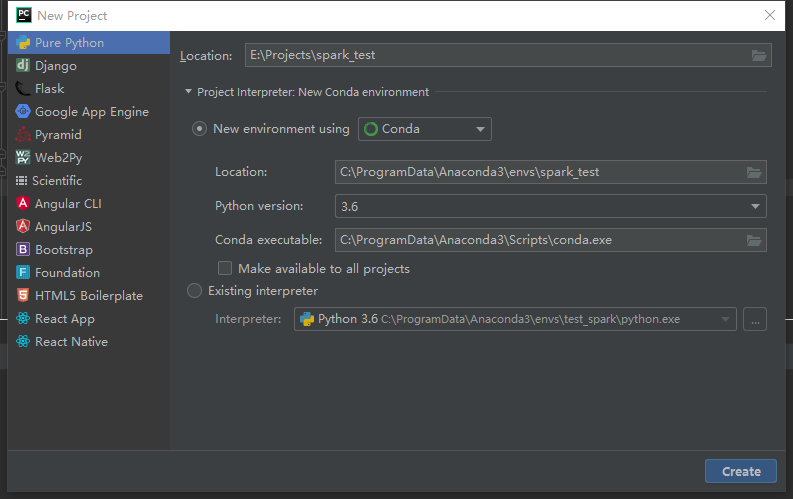
一段时间后我们的基本环境就创建完成了。
接着我们到项目设置中的project interpreter中添加py4j和pyspark包。

最后,我们要向pycharm中添加Spark的Libraries。
在project interpreter中点击那个小箭头,选择show all,在弹出的选择框中,选择我们是虚拟环境然后点击右侧显示path的小图标,在打开的对话框中新增
%SPARK_HOME%\python
%SPARK_HOME%\python\lib\py4j-0.10.7-src.zip
也可以直接写路径,或者使用环境变量,然后确定。
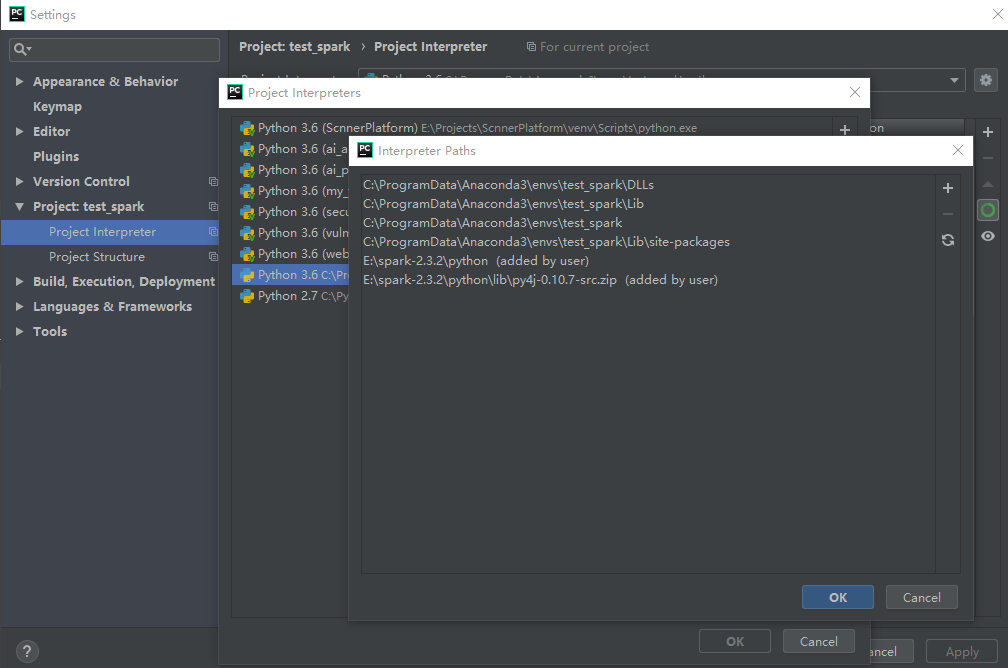
最后建议在我们py文件对应的环境变量配置中添加上python文件的路径,如下图。
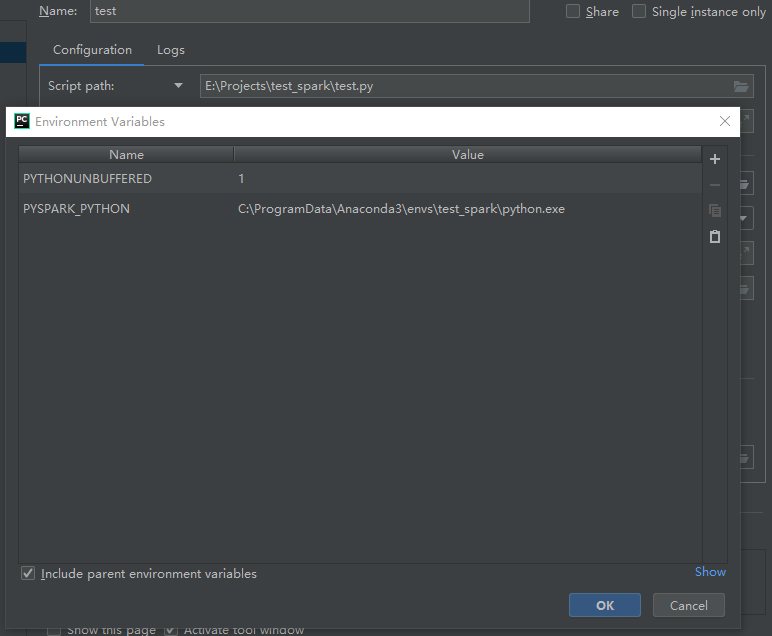
至此,我们所有的配置都完成了。
3、测试
from pyspark import SparkContext
sc = SparkContext('local')
doc = sc.parallelize([['a', 'b', 'c'], ['b', 'd', 'd']])
words = doc.flatMap(lambda d: d).distinct().collect()
word_dict = {w: i for w, i in zip(words, range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict_new = {}
wd = word_dict_b.value
for w in d:
if wd[w] in dict_new:
dict_new[wd[w]] += 1
else:
dict_new[wd[w]] = 1
return dict_new
print(doc.map(wordCountPerDoc).collect())
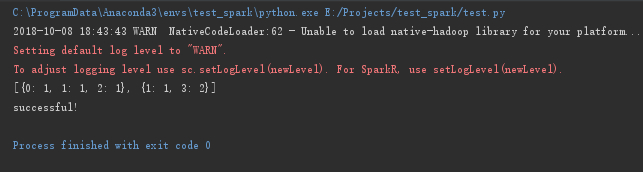
print("successful!")我们使用上面的代码进行测试,如果可以正常输出结果,则证明我们配置成功。

发表评论 /